Scattered Code Held My AI Back — 4 Weeks Moving to a Monorepo While Keeping MSA
24 Jun 2026
I decided to restart my stalled business, Caor. The problem wasn’t my stamina — it was the environment setup that tripped me up every single time.
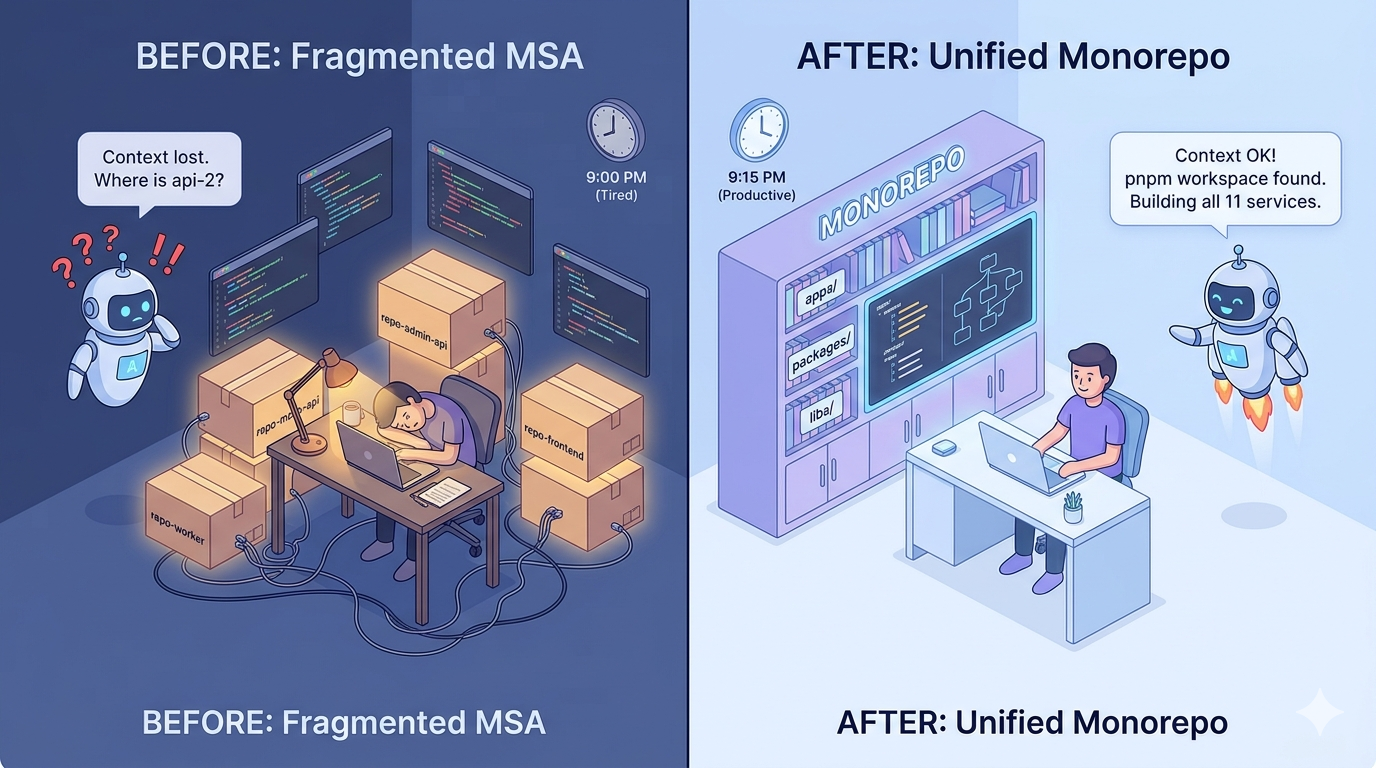
9 PM, and my brain has shut down
After a 3-hour round-trip commute plus a full day at work, I come home with a tired body and full-on brain fog. Trying to restart the stalled Caor in that state, the answer was only one: delegate a lot to AI. Hand off well-scoped work and development runs semi-automatically. Progress happens even with a stopped brain.
But I kept getting stuck in the same place. Environment setup. Each service had its own repo, its own startup procedure, and just explaining to the AI “right now this service calls that service like this” was itself a chore. I’d burn out before I even got to assigning the actual work.
This post is a record of slowly working through that bottleneck over four weeks. It’s still ongoing.
Why MSA in the first place — it was the right call back then
Caor was scattered across microservices. Around main-api (PHP + Laravel), several services each deployed from their own repos. The reasons were clear.
- No time. Writing each service independently and deploying them separately was faster in the moment.
- Easy to manage. Fix one thing, ship just that one thing.
- Easy to adopt new tech. Each service could freely layer on a different stack.
Distribution was a reasonable choice. But that reasonableness was a calculation premised on “people split the load.”
The one thing the AI era changed — the cost of context
Over the last few months, deployment, Kubernetes operations, and UI/UX improvements have become far easier than before. Attaching AI widened the range I could reach on my own.
The problem was that the tech changes too fast. When I tried to modernize the code to keep up with what just came out, the code was scattered across N repos, so I couldn’t touch it all at once. Change one place and the others wouldn’t follow.
The more essential issue is this. To delegate development to AI, you have to give it context — but with MSA that context is split into N pieces. Spin up one service, explain the neighboring repo, tell it the dependency between the two… and my evening was gone before the AI even started working.
Distribution was the right answer when people split the load. Once the collaborator became AI, the value of “having it all within a single context” flipped.
Decision: monorepo ≠ monolith
Let me head off the misunderstanding first. I didn’t abandon microservices. The runtimes are still separate — services each deploy independently. What I merged wasn’t the architecture, it was the repo.
There were two goals.
- Give AI a single context. With everything in one repo, dependencies and rules read in one pass.
- Make environment setup one-shot. Even on a tired evening, two lines should bring up the whole thing.
Boiled down to one line: “Keep MSA, but gather the code in one place.”
What I chipped away at over 4 weeks
Monorepo skeleton. Using a pnpm workspace, I gathered 11 services under apps/ into one repo. Three frontends (Next.js · Quasar/Vue · Vite/React) and the backends/workers all live in one place.
Single source of version truth. I dropped nvm and switched to mise. mise.toml pins Node 26 and the pnpm version. I structurally eliminated “but it works on my laptop.”
One-shot bootstrap. pnpm bootstrap:<target> idempotently lays down DB, migrations, seeds, and .env, and pnpm up:<target> brings up the whole stack on a single mprocs TUI screen. After git clone, two lines and you’re done. This is effectively the core deliverable of this migration.
Reproducibility trick. I fixed the docker compose project name to caor-mono. That way the network name is always the same regardless of the clone directory, so the --network commands baked into the docs don’t break.
The legacy doesn’t get killed. main-api and a few services stay PHP + Laravel as-is. I hung them onto the monorepo as git submodules. Instead of overhauling everything at once, I move the small ones first — the strangler approach. There’s no reason to forcibly halt something that works.
But what should move, moves. A few of the Laravel-based API servers that were scattered across MSA I ported to NestJS. The reason is to keep DTOs and validation as a single source. With PHP you can’t share types and validation rules with the frontend (TypeScript), but moving to NestJS lets you define DTOs and validation once, in one place, and reuse them all the way to the client. It’s another reason the monorepo becomes “same language, same context.”
Put the context AI will read right next to the code. I baked the service dependency map and proxy rules into AGENTS.md, and turned the dependency graph into a committed asset with Graphify so the AI queries the graph first before digging through raw source. Via MCP I connected the production k8s cluster as readonly, and the DB only for the local dev environment.
Port small services first → redeploy → clean up what blew up. I left the big main-api alone and pulled the easy-to-move ones into the monorepo first.
What Actually Broke (And Why That’s the Point)
Port collisions. The services were all defaulting to the same ports (e.g. 3000, 8000). So I made a convention table assigning each service its own unique port (e.g. separating services into the 30xx band). Since the code fallback was the default, I had to force the port in env.
Proxy traps. The same /api prefix points to different services per app. partner/customer’s /api is the legacy main-api, but admin’s /api is admin-api. The AI kept inferring the wrong service from the prefix alone, so I nailed this down as the “most important rule” in AGENTS.md. Giving AI context ultimately means writing down traps like these.
Seed idempotency. I fixed the dev seed so it doesn’t break no matter how many times you run it. In a semi-automated routine, idempotency is non-negotiable — if it’s not idempotent, a human has to look at it every single time.
Even the legacy PHP version via mise. For the legacy image-api hung as a submodule, I pinned even the PHP version with mise and attached an auto-start script. If a legacy environment runs wild, the one-shot breaks.
It’s not done yet, and that’s normal
main-api is still PHP/Laravel. I have no intention of moving everything yet. Especially an API like main-api that many things depend on carries a big risk of blowing up if ported carelessly. So for APIs like this, I plan to first lay down e2e and scenario tests to pin the behavior, then port. The monorepo isn’t “complete” — it’s a foundation.
What changed is this. Now I can give the AI context all at once, and the environment comes up in two lines. The conditions are in place for work to keep rolling even with a stopped brain at 9 PM. It wasn’t a grand re-architecture — it was work to let a tired person keep working.
If you’re in a similar spot
For someone on a small team, drained every evening, who still wants to delegate to AI and keep something running.
You don’t need to abandon MSA. Gather the scattered repos, make the environment one-shot, and put the context docs AI will read right next to the code — that’s where it starts.
The cost of distribution was calculated with people as the baseline. If your collaborator has become AI, you have to redo that calculation from scratch.